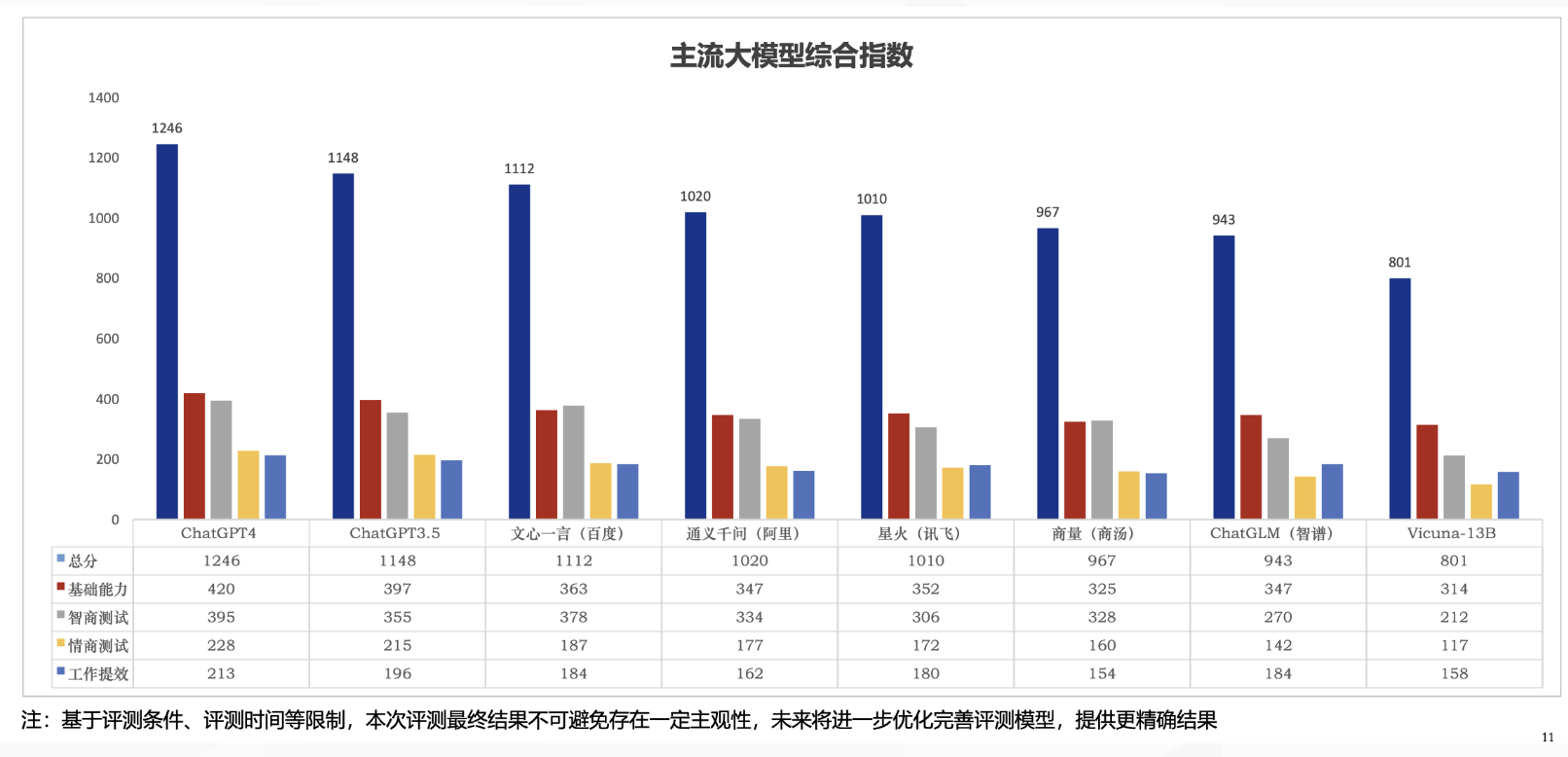
近日��,新華社研究院中國企業(yè)發(fā)展研究中心對主流大模型產(chǎn)品進行了體驗評測���,發(fā)布了《人工智能大模型體驗報告》��?���!秷蟾妗凤@示����,百度文心一言總得分位居國內第一,并在基礎能力����、智商��、情商�、工作提效等維度均獲國內第一�����。在智商測試部分��,百度文心一言意外超過ChatGPT3.5��,表現(xiàn)突出���,位居排名第二�����,僅次于GPT4�。
在綜合指數(shù)評價方面����,本次評測選取4大維度(基礎能力、智商測試��、情商測試、工作提效能力)����、36個子能力,共300個問題���,對目前主流大模型產(chǎn)品進行測試。
同時���,研究院還邀請相關專家組成評測團隊深入分析各個產(chǎn)品的語義理解�、知識儲備��、邏輯能力等��,最終得出各廠商的大模型綜合指數(shù)評價�。
綜合評測結果顯示:ChatGPT系列模型各項指標表現(xiàn)優(yōu)異,Chat-GPT4.0版本各項能力在3.5版本的基礎上均有一定程度提升�����。
由百度開發(fā)的人工智能大模型文心一言是目前國內自主研發(fā)的大模型中具有優(yōu)勢的產(chǎn)品�����。其余大模型產(chǎn)品也在基礎能力方面表現(xiàn)優(yōu)良�,但面對較復雜的工作內容或情商環(huán)境仍有不同程度的進步空間�。
免責聲明: 本文內容來源于快科技 ����,不代表本平臺的觀點和立場。
版權聲明:本文內容由注冊用戶自發(fā)貢獻��,版權歸原作者所有����,武岡人網(wǎng)僅提供信息存儲服務,不擁有其著作權�����,亦不承擔相應法律責任�。如果您發(fā)現(xiàn)本站中有涉嫌抄襲的內容,請通過郵箱(admin@4305.cn)進行舉報����,一經(jīng)查實,本站將立刻刪除涉嫌侵權內容���。